Mimo Code 爆火:我们挖开源代码,找到小米 AI 的真创新
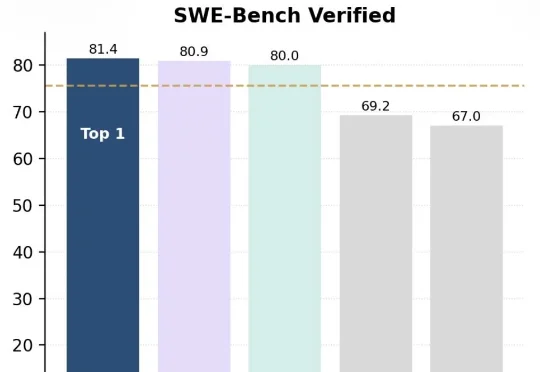
Mimo Code 爆火:我们挖开源代码,找到小米 AI 的真创新6 月 11 日凌晨,小米 MiMo 团队公开了一个叫 MiMo Code 的项目,定位是终端编程 Agent,MIT 协议开源。官方宣传重点有三处,14 天 5 人团队投入的“vibe coding”开发叙事、Claude Code 之上的 SWE-Bench Pro 跑分。以及“无限上下文”的记忆架构。
来自主题: AI技术研报
9809 点击 2026-06-24 16:35